 |
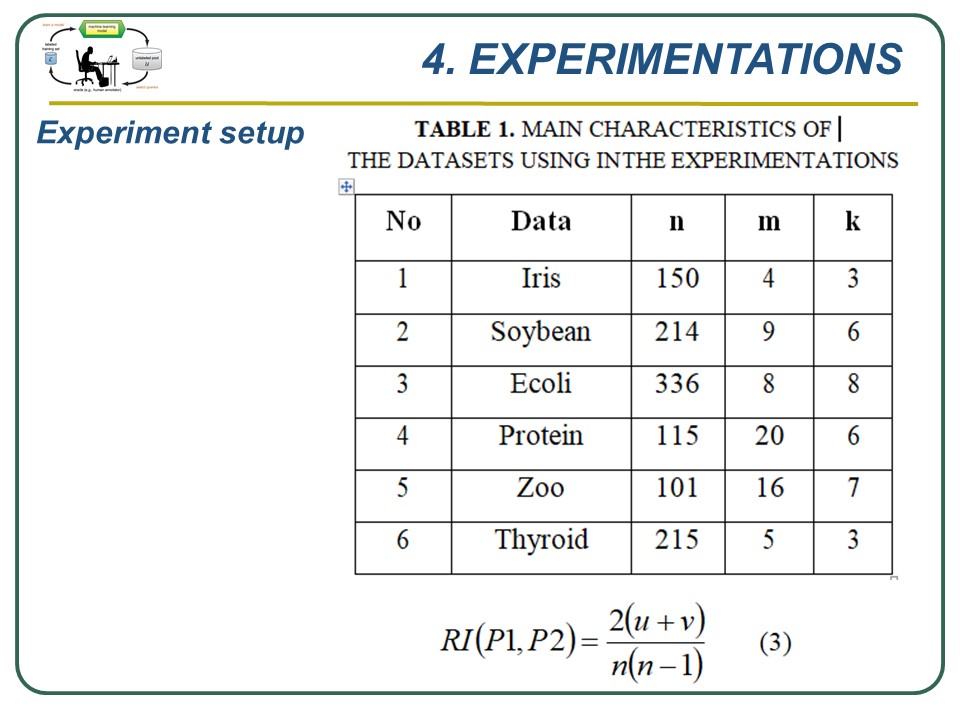
We conduct experiments to evaluate our new algorithm, we have used 6 data sets from UCI machine learning, at table 1 in which n is the number of data points , m is the number of attributes, and k is the number of clusters.
We use the MCSSGC, a semi-supervised graph-based clustering algorithm, to measure the effectiveness of constraints collected by our algorithm.
To estimate the clustering efficiency, we have used the Rand Index (R-I) measure (see equation 3) (The R-I calculates the agreement between the theoretical partition - P1; and the output partition - P2 of each data set by the evaluated clustering algorithm)
To compare two partitions P1 and P2, let u be the number of decisions where xi and xj are in the same cluster in both P1 and P2. Let v be the number of decisions, where the two points are put in different clusters in both P1 and P2.
The value of RI is in the interval [0ˇ¦1]; R-I = 1 when the clustering result corresponds to the ground truth or user expectation. The higher the R-I, the better the result. |
 IEEE/ICACT20220071 Slide.11
[Big Slide]
IEEE/ICACT20220071 Slide.11
[Big Slide]