 |
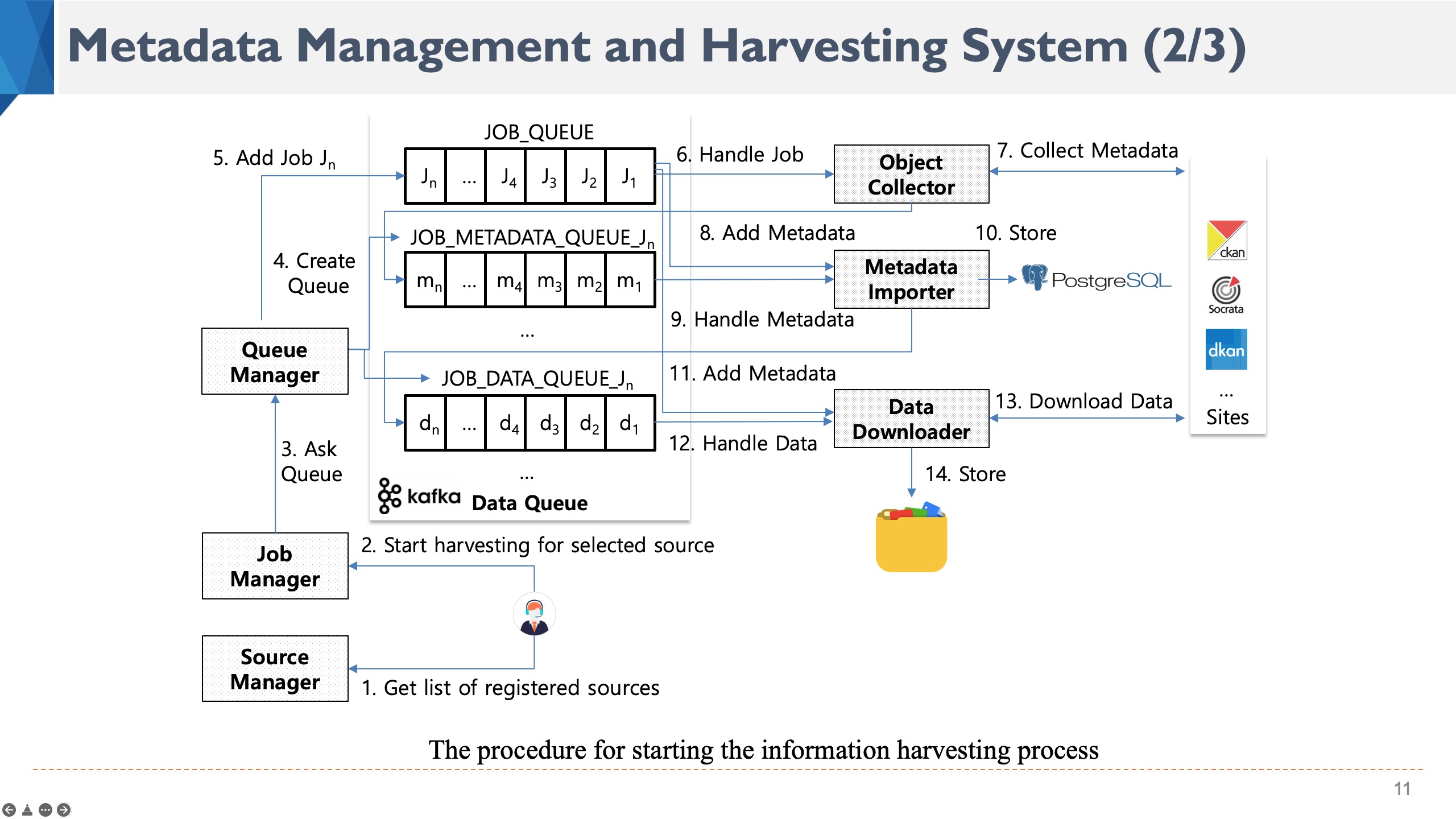
This is the scenario for starting the information harvesting process in our system. In the first step, user sends a request to Source Manager for obtaining a list of registered sources. User then selects one source and sends a request to Job Manager for starting the information harvesting process of that source. Based on the job information in database, the Job Manager checks whether there is any invalid information in the request or not. After that Job Manager asks Queue Manager to create a new meatadata queue and data queue for job Jn and add job Jn into the JOB_QUEUE queue. Object Collector gets job Jn from JOB_QUEUE queue, asks Config Manager for configuration information and Source Manager for source information. Object Collector then sends requests to the external system for obtaining a list of dataˇŻs metadata and asks Queue Manager to add the items of this list into the metadata queue of job Jn. Metadata Importer gets metadata Mn from metadata queue and performs mapping the properties of Mn with the standard based on the configuration information and store the mapped Mn into database. Metadata Importer then asks Queue Manager to add the items of metadata list which include direct data content download endpoints to the data queue for job Jn. Finally, Data Downloader gets metadata dn from queue, performs downloading dn and stores the result into the appointed storage system in Data Storage. |
 IEEE/ICACT20220341 Slide.11
[Big Slide]
[YouTube]
IEEE/ICACT20220341 Slide.11
[Big Slide]
[YouTube]