 |
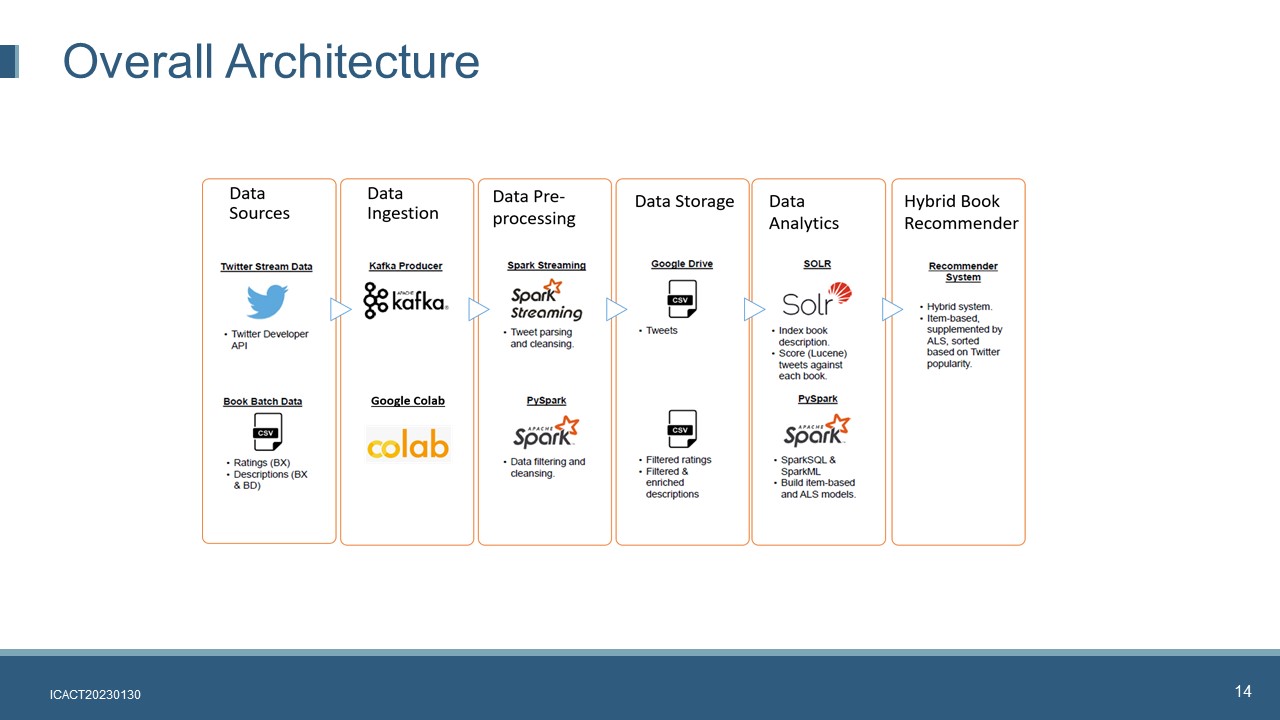
The proposed hybrid book recommender system is implemented on top of a big data framework.
It consists of six layers.
Data Source. The streaming tweets are extracted by using Twitter developer API. The book dataset was retrieved from Kaggle book dataset repository
Data Ingestion. Twitter streaming data is ingested using Apache Kafka. Tweepy, an easy-to-use Python library for accessing the Twitter API, allows us to connect the Twitter API and listen for tweets. Google Colab is used to upload book dataset including book crossing rating and book description files into Google Drive.
Data Pre-processing. Apache Spark Streaming is used to clean the tweets. Apache Spark Stream is subscribed to the KafkaĄŊs Twitter topic. The original data format is JSON format, we need to define new schema and extract the useful fields by using Spark Streaming. The processed and cleansed tweets will be exported and save as CSVs. PySpark is used to cleanse, filter and integrate data
Data Storage. Both the cleansed tweets and book rating files are saved in Google Drive for further use
Data Analytics. This layer will implement two major tasks: Lucene score calculation and recommender system model building. Apache Solr provides a user-friendly GUI for query test as well as a REST API for query calls. Each booksĄŊ Lucene scores are saved as a CSV and uploaded onto Google Drive. The item-based collaborative filtering algorithm is combined with a model derived from the ALS algorithm in the hybrid recommender system. Because the Apache Spark MLlib does not provide a ready-made item-based model, we use an item-based algorithm from [22] and make necessary modification to some of the functions to implement the item-based recommender algorithm. The ALS model is implemented by using Apache Spark MLlib.
Hybrid Recommender System. We create a hybrid recommender system by combining the item-based model, the ALS model and the booksĄŊ popularity scores (Lucene scores). The use of both models can supplement the shortcomings of each individual model. For example, the full matrix generated by ALS partially mitigates data sparsity issues that cause the item-based model to fail to make recommendations. BooksĄŊ popularity is determined by the Lucene scores which are used to prioritize the book recommendations.
|
 IEEE/ICACT20230130 Slide.14
[Big Slide]
[YouTube]
IEEE/ICACT20230130 Slide.14
[Big Slide]
[YouTube]