 ICACT20230130 Slide.25
[Big slide for presentation]
[YouTube]
ICACT20230130 Slide.25
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! Click!! |
 |
Thank you. Now, open to Q&A.
|
|
ICACT20230130 Slide.24
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
Reference list
|
|
ICACT20230130 Slide.23
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
In this research work, we Proposed a hybrid book recommender system to make personalized recommendations for users.
Used the item-based algorithm with the ALS to solve the sparsity problem and address the over-fitting issue.
Given the book popularity, we used the Twitter Developer API to collect streaming tweets in order to prioritize the book recommendations. We calculated the Lucene score of a book by querying the collected tweets against its description. This gave us a numerical representation of how “popular” the book is right now.
Our proposed system was implemented using a big data framework. Apache Kafka and Apache Spark Streaming were used to ingest and process Twitter streaming data. PySpark was used to implement data pre-processing and data analytics. The ALS recommender algorithm was implemented using Apache Spark MLlib. The results showed that the accuracy of the proposed hybrid recommender system was acceptable and it assisted readers in finding appropriate books among a flood of information.
In the future, we intend to improve our model by incorporating book bibliography data such as publisher, author and category as well as users’ demographic data. Regarding the big data framework, we intend to deploy the proposed hybrid recommender system on cloud platforms such as AWS Cloud or Google Cloud Platform.
|
|
ICACT20230130 Slide.22
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
Conclusion & Future work
|
|
ICACT20230130 Slide.21
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
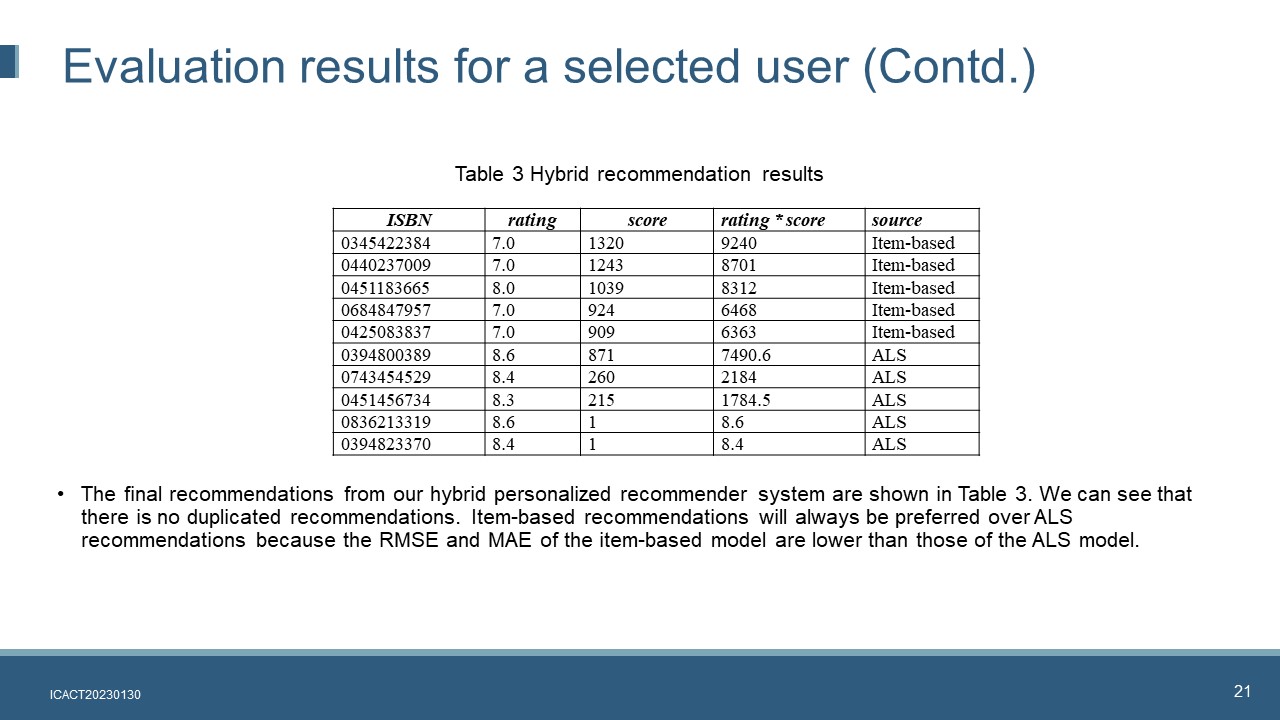 |
The final recommendations from our hybrid personalized recommender system are shown in Table 3. We can see that there is no duplicated recommendations. Item-based recommendations will always be preferred over ALS recommendations because the RMSE and MAE of the item-based model are lower than those of the ALS model.
|
|
ICACT20230130 Slide.20
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
We select User-ID = 46671 at random to demonstrate the proposed hybrid book recommender algorithm.
The RMSE for the item-based model is 1.7670 and the MAE is 1.1331, whereas the RMSE for the ALS model is 2.0047 and the MAE is 1.6421. The item-based model performs slightly better than the ALS.
The 5 books recommended by item-based model combined with the book popularity is shown in TABLE 1. The 5 books recommended by ALS model combined with book popularity is shown in TABLE 2.
|
|
ICACT20230130 Slide.19
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
The following steps describes the workflow of our hybrid recommender system which combines the item-based, the ALS model and the book popularity derived from the collected tweets.
Step1: Both item-based and ALS models will recommend N number of books for a user. E.g., if N = 5, the item-based model will generate 5 recommendations and the ALS will generate 5 recommendations, giving a total of 10 recommendations (assuming there are no duplicated recommendations from these two models).
Step2: Retrieve Lucene score for each recommended book.
Step3: Calculate the combined ranking for each recommended book.
Step4: Sort recommendations based on the following rules:
Item-based recommendations will always come first, followed by ALS recommendations.
Then the recommendations from each model will be sorted based on the combined ranking.
Drop duplicate recommendations in the ALS model if it is already recommended by the item-based model.
|
|
ICACT20230130 Slide.18
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
Total dataset is split into a training and test set in a 4:1 ratio.
Two measure metrics RMSE and MAE are used to evaluate the performance of the recommender algorithm.
RMSE emphasizes on larger absolute errors. The lower the RMSE is, the more accurate is the recommendation.
In the RMSE calculation formula, 𝑝_(𝑢,𝑖) is the predicted rating of user 𝑢 on item 𝑖, 𝑟_(𝑢,𝑖) is the actual rating of user 𝑢 on item 𝑖.
MAE is the most popular and commonly used measurement metrics to evaluate prediction model. It is a measure of deviation of recommendation from user’s specific value.
In the MAS calculation formula, 𝑝_(𝑢,𝑖) the predicted rating from user u on item i , 𝑟_(𝑢,𝑖) is the actual rating from user u on item i, N is the total number of ratings on the item set. The lower the MAE, the better the recommendation algorithm predicts user’s ratings.
|
|
ICACT20230130 Slide.17
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
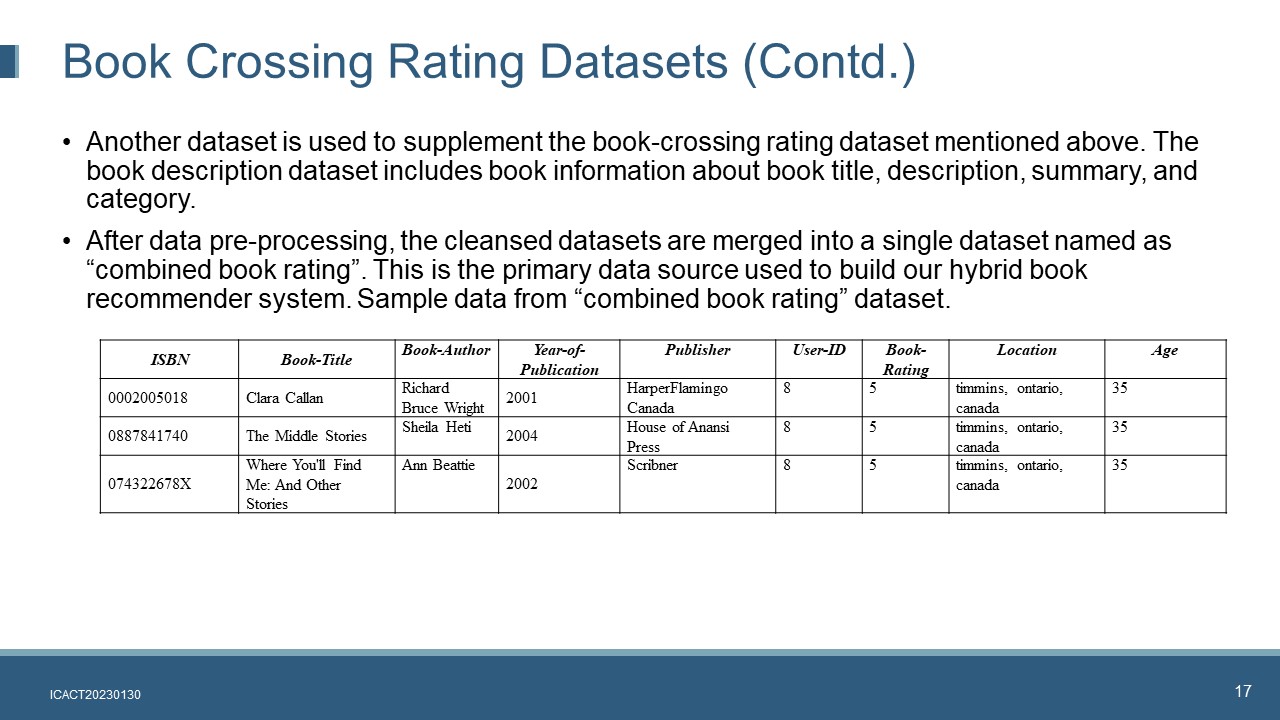 |
Another dataset is used to supplement the book-crossing rating dataset mentioned above. The book description dataset includes book information about book title, description, summary, and category.
After data pre-processing, the cleansed datasets are merged into a single dataset named as “combined book rating”. This is the primary data source used to build our hybrid book recommender system. Sample data from “combined book rating” dataset.
|
|
ICACT20230130 Slide.16
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
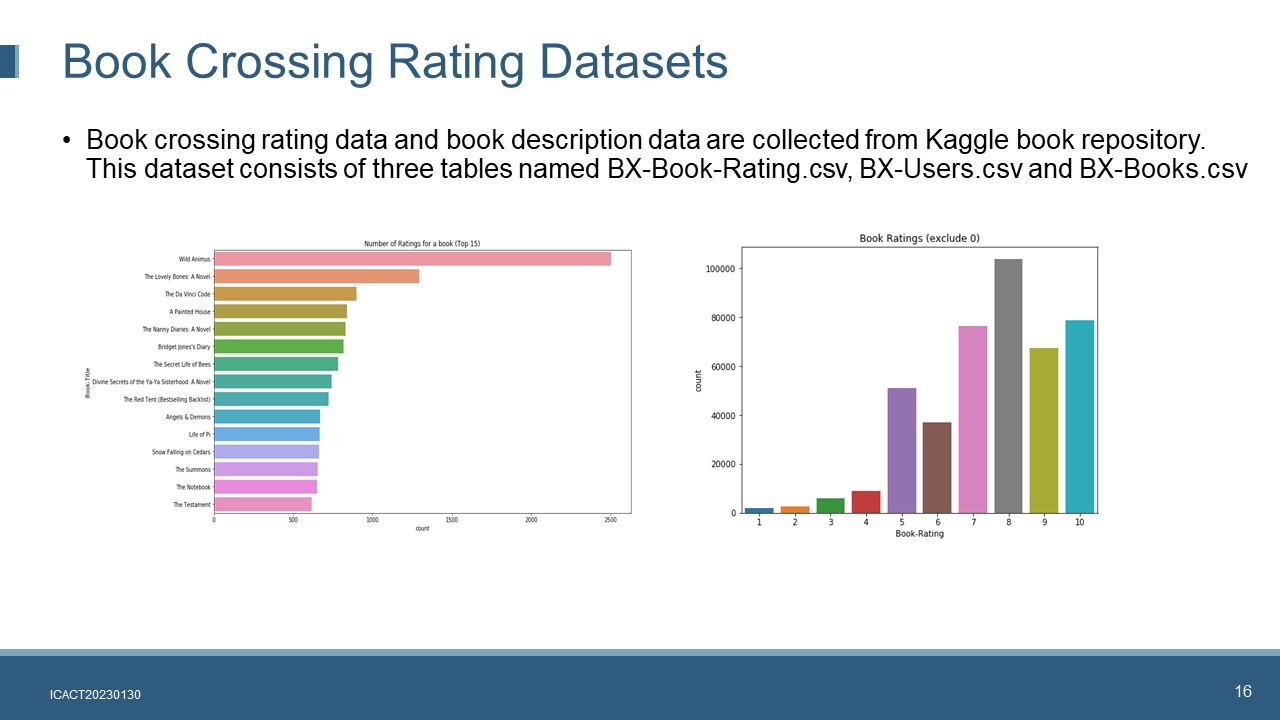 |
Book crossing rating data and book description data are collected from Kaggle book repository. This dataset consists of three tables named BX-Book-Rating.csv, BX-Users.csv and BX-Books.csv
Exploratory data analysis is conducted to understand the statistical distribution of the book dataset. The Top 15 number of ratings (exclude 0 ratings) for a book is shown in the graph at the left. Book rating distribution is shown in the graph at the right.
|
|
ICACT20230130 Slide.15
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
Experimental results
|
|
ICACT20230130 Slide.14
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
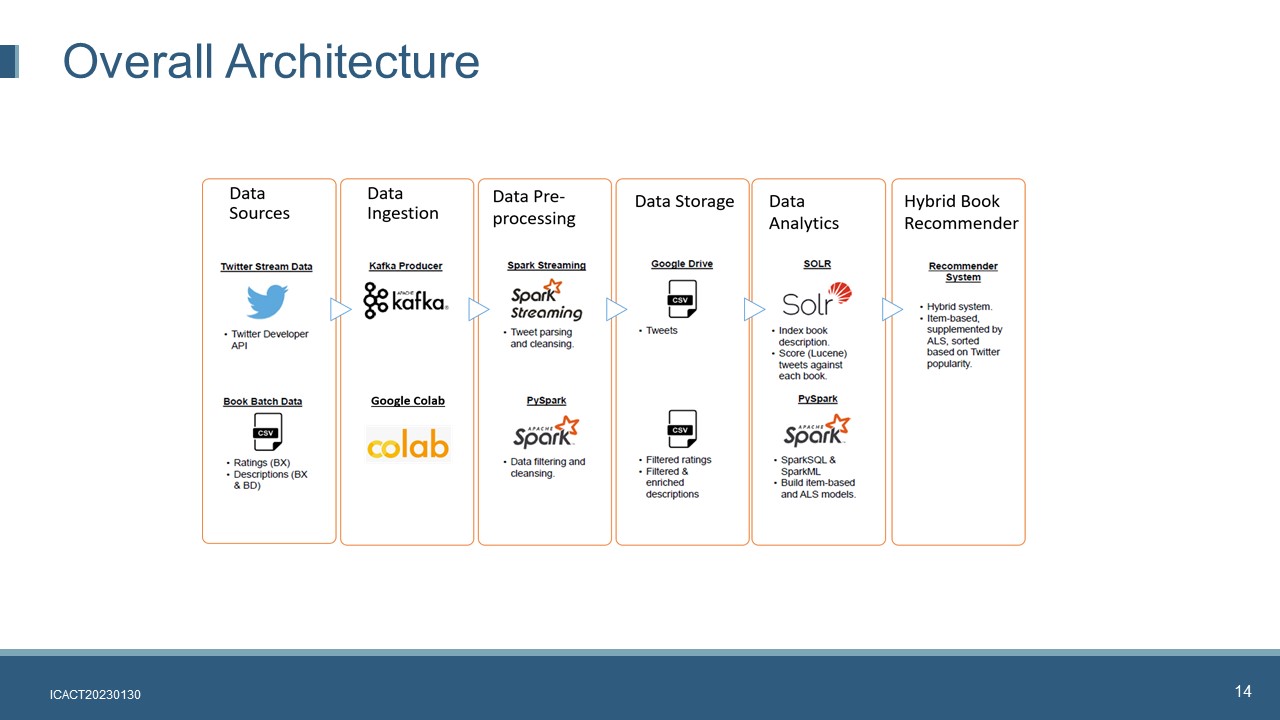 |
The proposed hybrid book recommender system is implemented on top of a big data framework.
It consists of six layers.
Data Source. The streaming tweets are extracted by using Twitter developer API. The book dataset was retrieved from Kaggle book dataset repository
Data Ingestion. Twitter streaming data is ingested using Apache Kafka. Tweepy, an easy-to-use Python library for accessing the Twitter API, allows us to connect the Twitter API and listen for tweets. Google Colab is used to upload book dataset including book crossing rating and book description files into Google Drive.
Data Pre-processing. Apache Spark Streaming is used to clean the tweets. Apache Spark Stream is subscribed to the Kafka’s Twitter topic. The original data format is JSON format, we need to define new schema and extract the useful fields by using Spark Streaming. The processed and cleansed tweets will be exported and save as CSVs. PySpark is used to cleanse, filter and integrate data
Data Storage. Both the cleansed tweets and book rating files are saved in Google Drive for further use
Data Analytics. This layer will implement two major tasks: Lucene score calculation and recommender system model building. Apache Solr provides a user-friendly GUI for query test as well as a REST API for query calls. Each books’ Lucene scores are saved as a CSV and uploaded onto Google Drive. The item-based collaborative filtering algorithm is combined with a model derived from the ALS algorithm in the hybrid recommender system. Because the Apache Spark MLlib does not provide a ready-made item-based model, we use an item-based algorithm from [22] and make necessary modification to some of the functions to implement the item-based recommender algorithm. The ALS model is implemented by using Apache Spark MLlib.
Hybrid Recommender System. We create a hybrid recommender system by combining the item-based model, the ALS model and the books’ popularity scores (Lucene scores). The use of both models can supplement the shortcomings of each individual model. For example, the full matrix generated by ALS partially mitigates data sparsity issues that cause the item-based model to fail to make recommendations. Books’ popularity is determined by the Lucene scores which are used to prioritize the book recommendations.
|
|
ICACT20230130 Slide.13
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
Overall architecture
|
|
ICACT20230130 Slide.12
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
In summary, in the hybrid book recommender system, item-based algorithm recommendations will always come first, followed by the ALS recommendations. The book popularity will be used to sort the recommendations for each algorithm. In order to combine both book popularity and recommender algorithms, the combined book ranking will be calculated by considering both the model-based algorithms as well as the book popularity. Recommendation list generated by each algorithm will be sorted based on the combined ranking.
|
|
ICACT20230130 Slide.11
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
Tweets from Twitter’s public timeline are collected and analyzed to identify the book popularity. Popular books are those that are mentioned frequently in tweets.
Apache Solr is used to calculate the Lucene score. Apache Solr is comprised of three main components: an indexer, a Lucene index and a server . To determine the popularity of a book, relevant tweets are collected from Twitter using Twitter Developer API and passed on as queries to the Apache Solr server. The server retrieves the book's description associated with the tweet content along with a weight that indicates the similarity between the query and the book's description for each gathered tweet. These books are sorted based on the total weight of their tweets. As a result, the books are ranked according to their popularity (indicated by Lucene score). The more popular the book is, the higher is the Lucene score.
|
|
ICACT20230130 Slide.10
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
Because the ALS algorithm generates a full matrix, it is always able to make recommendations.
There are two k dimensional vectors which are referred to as “factor”.
𝑥_𝑢 is k dimensional vectors summarizing’s every user u.
𝑦_𝑖 is k dimensional vectors summarizing’s every item i.
Use stochastic gradient descent to minimize the squared error between the predicted rating the actual rating,
Here, 𝜆 is the regularization factor, which is used to address the over fitting issue, is referred as weighted- 𝜆-regularization. The default value of 𝜆 is 1.
|
|
ICACT20230130 Slide.09
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
Our proposed personalized book recommender algorithm uses an item-based technique rather than a user-based technique. Since the number of users is more than the number of books in the cleansed dataset, user-based collaborative filtering is more likely to have the sparse problem than the item-based filtering.
One critical step in the item-based collaborative filtering algorithm is to calculate the similarity between items and then to select the most similar items. Here, We compute the similarity between items 𝑖 and 𝑗 using the adjusted cosine similarity by using the first formula.
where 𝑟_(𝑢,𝑖) is the rating of user 𝑢 on item 𝑖, 𝑟_(𝑢,𝑗) is the rating of user 𝑢 on item 𝑗, (𝑟_𝑢 ) ̅ is the mean rating of user 𝑢, 𝑈 is the set of all users. Each individual rating is within a scale from 0 to 10. Rating 0 indicates that the user has not yet rated this book.
Once we have the similarities between the items 𝑖 and 𝑗, we can predict user 𝑢’s rating for an item 𝑖 using the second formula.
As item-based approach relies on calculating the similarities between each book, there will be scenarios where this is not possible since there are insufficient overlapping ratings. For example, for some users, the model is unable to make any or a few recommendations (e.g., less than 5 books). In this case, the rating matrix 𝑅 is a sparse matrix because items do not receive ratings from a large number of users which leads to 𝑅 containing many missing values.
To address this issue, ALS approach is used to supplement the item-based approach. One solution to the sparse matrix problem is ALS matrix factorization.
|
|
ICACT20230130 Slide.08
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
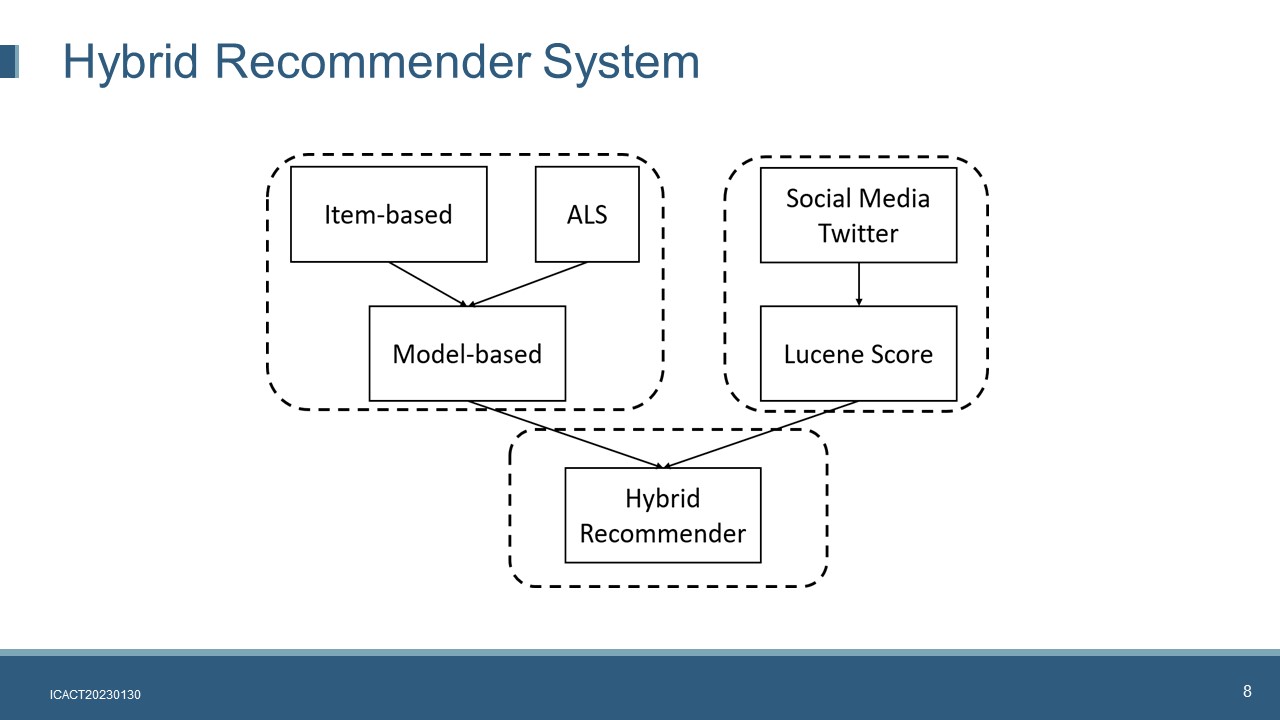 |
This is the architecture of the hybrid book recommender system. The system consists of three modules
Model-based book recommender algorithm. It recommends N number of books to a user based on the item-based algorithm and the ALS algorithm.
Lucene score calculation. It is used to prioritize books that are deemed more popular based on the relevant Twitter tweets.
Hybrid Recommender. Item-based recommendations will always come first, followed by the ALS recommendations. The book popularity will be used to sort the recommendation list of each algorithm.
|
|
ICACT20230130 Slide.07
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
In this session, we will describe our hybrid personalized book recommender system in details.
|
|
ICACT20230130 Slide.06
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
However, those recommender systems did not consider the current reading trends when making book recommendations. How to use social media information to detect current reading trends is an interesting research direction. Another critical issue of current recommender systems is the scalability of algorithms with large amounts of data. Dealing with massive amounts of dynamic data generated by online interactions between users and online book platforms is a challenge.
We use social media information to detect current reading trends and combine the book popularity and personal interests to recommend books.
Book popularity is identified by the collected tweets to indicate current reading trends. The book popularity is represented by Lucene score of each book based on the collected tweets.
We implement the proposed hybrid book recommender system on top of big data frameworks such as Apache Spark, Apache Kafka, Spark MLLib and Apache Solr.
Our system provide the scalability of algorithms with large amount of data.
|
|
ICACT20230130 Slide.05
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
A lot of book recommender systems have been developed using different recommendation techniques.
Okon et. al., 2018, designed and developed an improved recommendation model by using collaborative filtering algorithm as well as an efficient quick sort algorithm to make efficient book recommendation. This system was implemented by using a real-time, cloud-hosted NOSQL database.
Chandak et. al., 2015, proposed a book recommender system that combines the features of collaborative filtering and content-based filtering in a hybrid way. It combines recommendations generated by two techniques.
Zafar. Ali, et. al., 2016, created a hybrid book recommender system that recommends relevant books based on book contents, item-item collaborative filtering and association rule mining.
|
|
ICACT20230130 Slide.04
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
In this session, we will present related work and our contribution.
|
|
ICACT20230130 Slide.03
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
Three main techniques are widely used to build recommender systems: collaborative filtering, content-based filtering and hybrid algorithm.
The collaborative filtering algorithm is the most widely used and the most matured technique. It is a process of filtering information or pattern based on the similarity between items.
Content-based algorithm is based on the matching of user profile and some specific characteristics of an item.
But single Recommender system algorithm has its own limitation.
Collaborative filtering performs well when there is sufficient rating information, but its performance is not good when the rating is sparse and has cold-start problem for new items.
Content-based filtering is able to handle the case of new items, but the items must be encoded with meaningful feature
hybrid algorithm combines the features of two or more recommender techniques to overcome the drawbacks of one recommender technique and obtain the advantages of different recommender techniques.
|
|
ICACT20230130 Slide.02
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
A Recommender systems aims to find and suggest items of likely interest based on users’ preferences.
It becomes an important factor for the success of e-commerce and other industries nowadays.
Netflix provides a subscription service model that offers personalized recommendations to help users to find shows and movies of users’ interest.
Amazon has developed recommender system to recommend products based on each user’s purchased and rated items.
Linked used recommender system to recommend jobs and colleagues.
|
|
ICACT20230130 Slide.01
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
Hi everybody, my name is Liu Fan. I am current is a lecturer and consultant in ISS, National University of Singapore. For ICACT 2023, I have cooperated with two partners: Dr Suria and Dr Venkatraman. Our presentation today is about creating a hybrid personalized book recommender system based on big data framework.
|









