 ICACT20220071 Slide.01
[Big Slide]
[YouTube] ICACT20220071 Slide.01
[Big Slide]
[YouTube] |
Chrome  Click!! Click!! |
 |
Hello everyone! I am Cong-Mau Tran. I am here today to present our work in ICACT 2022, named Active constraints selection based on density peak.
|
| ICACT20220071 Slide.02
[Big Slide]
|
Chrome Click!! |
 |
Our research addresses the problem of selecting good constraints for semi-supervised clustering algorithms. For this purpose, we propose an active learning algorithm for the constraints collection task, which relies on the min-max algorithm and peaks estimation based on density score. Experiments conducted on some real data sets from UCI show the effectiveness of our approach. |
| ICACT20220071 Slide.03
[Big Slide]
|
Chrome Click!! |
 |
The paper is organized as follows:
Sections 1: Introduction;
Sections 2: presents some Related word;
Section 3: introduces our new active selection method, while section 4 describes the experiments that have been conducted on benchmark datasets. Finally, section 5 concludes and discusses future research. |
| ICACT20220071 Slide.04
[Big Slide]
|
Chrome Click!! |
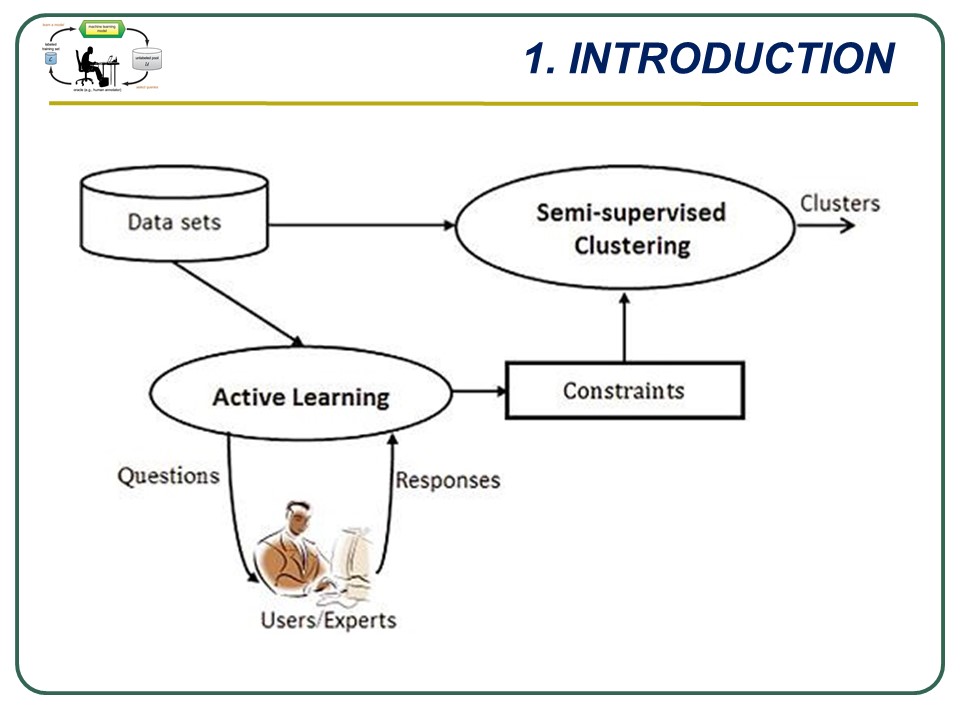 |
Recently, semi-supervised clustering has received a lot of attentions in researcher communities . The advantage of semi-supervised clustering consists in possibility to use a small set of side information to improve clustering results. Constraints include must-link and cannot-link. In real applications, we hypothesis that the side information is available or can be collected from users/experts. For example, in our research in 2020, A Density-based Approach for Querying Informative Constraints for Clustering, we studied that the general idea has been rising when we work with the semi-supervised clustering problem. The above figure shows a schema for semi-supervised clustering. |
| ICACT20220071 Slide.05
[Big Slide]
|
Chrome Click!! |
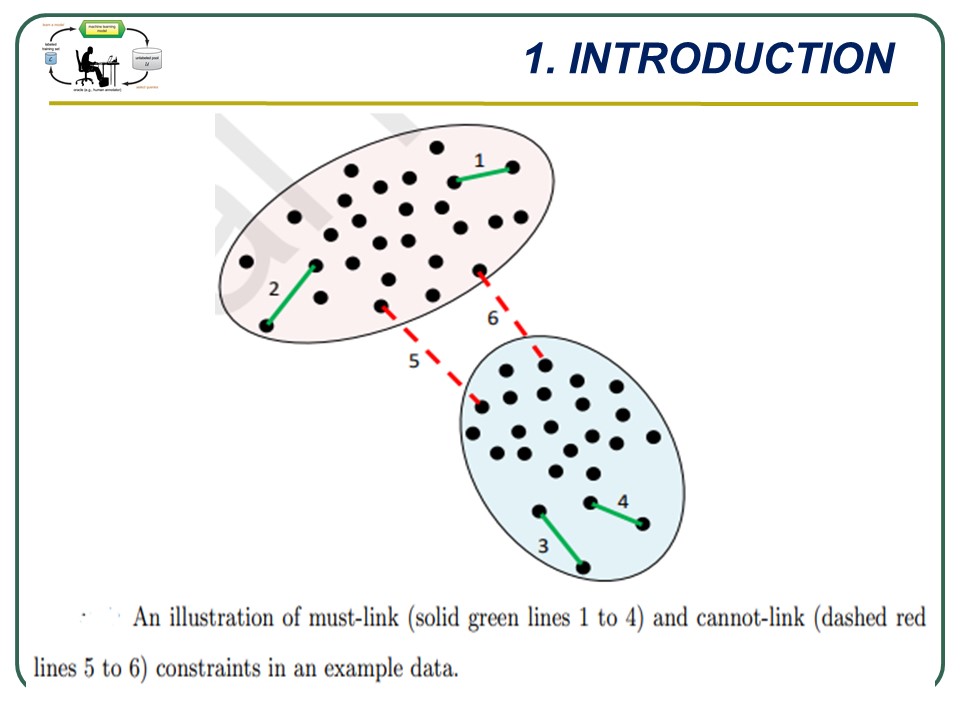 |
And another example as shown in the above Figure: A must-link constraint indicates that two points of the data set should be grouped in the same cluster while a cannot-link constraint imposes that the points should be grouped in different clusters. |
| ICACT20220071 Slide.06
[Big Slide]
|
Chrome Click!! |
 |
In this section, we will present some basic concepts using such as density peak detecting, active learning, and the min- max method. These methods will be used in our new algorithm in the next section.
Firstly, the Density peak detecting process.
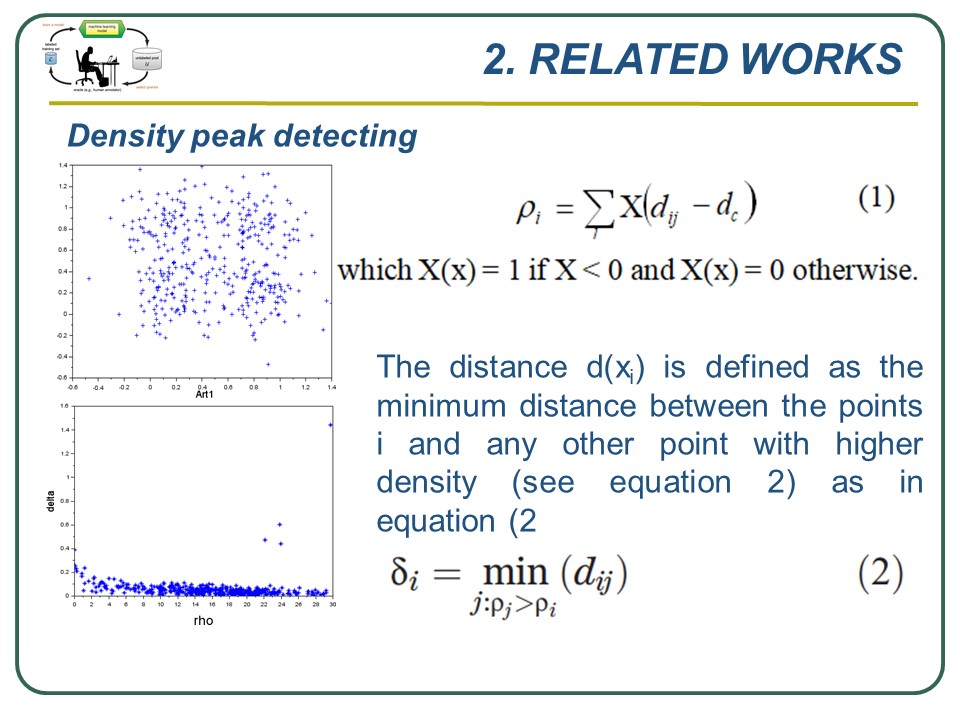
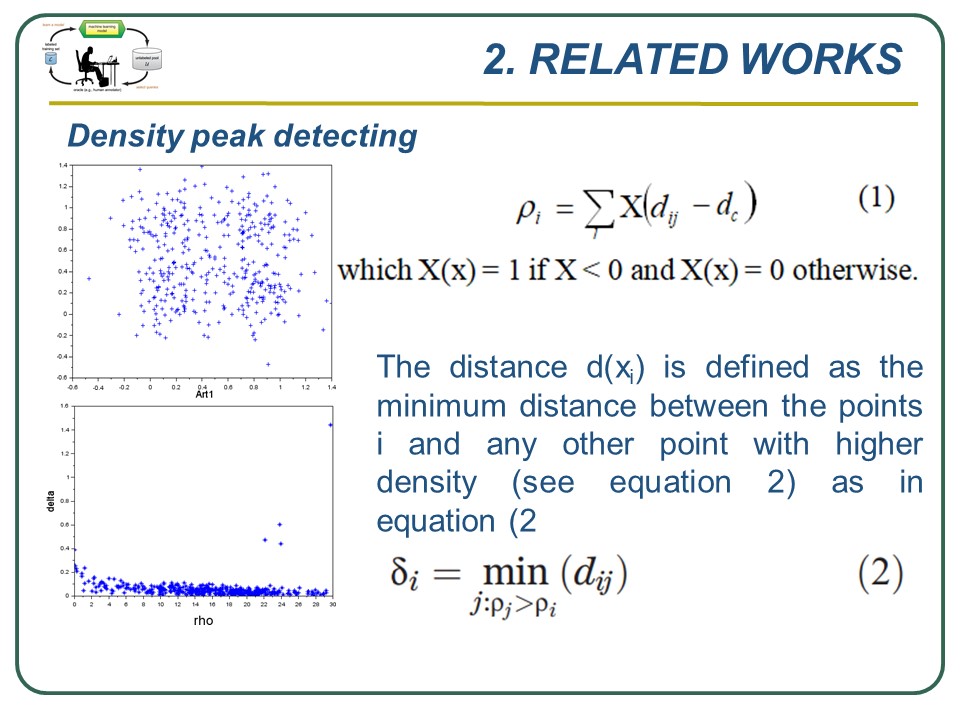
In 2014, Rodriguez and Laio proposed the density peak concept in the context of clustering problem. Using a parameter dc, the local density of xi is defined as equation 1 and 2.
From two factors r(xi) and d(xi), we can build a decision graph in which the x-axis and the y-axis are respectively the rho and delta values for whole data set. Date set Art1 (top) and the decision graph (bottom): four points in the right up corner of the figure can be seen as peaks of the decision graph. |
| ICACT20220071 Slide.07
[Big Slide]
|
Chrome Click!! |
 |
In this section, we will present some basic concepts using such as density peak detecting, active learning, and the min- max method. These methods will be used in our new algorithm in the next section.
Firstly, we explain the Density peak detecting process.
In 2014, Rodriguez and Laio proposed the density peak concept in the context of clustering problem. Using a parameter dc, the local density of xi is defined as equation 1 and 2. From two factors r(xi) and d(xi), we can build a decision graph in which the x-axis and the y-axis are respectively the rho and delta values for whole data set. Date set Art1 (top) and the decision graph (bottom): four points in the right up corner of the figure can be seen as peaks of the decision graph. |
| ICACT20220071 Slide.08
[Big Slide]
|
Chrome Click!! |
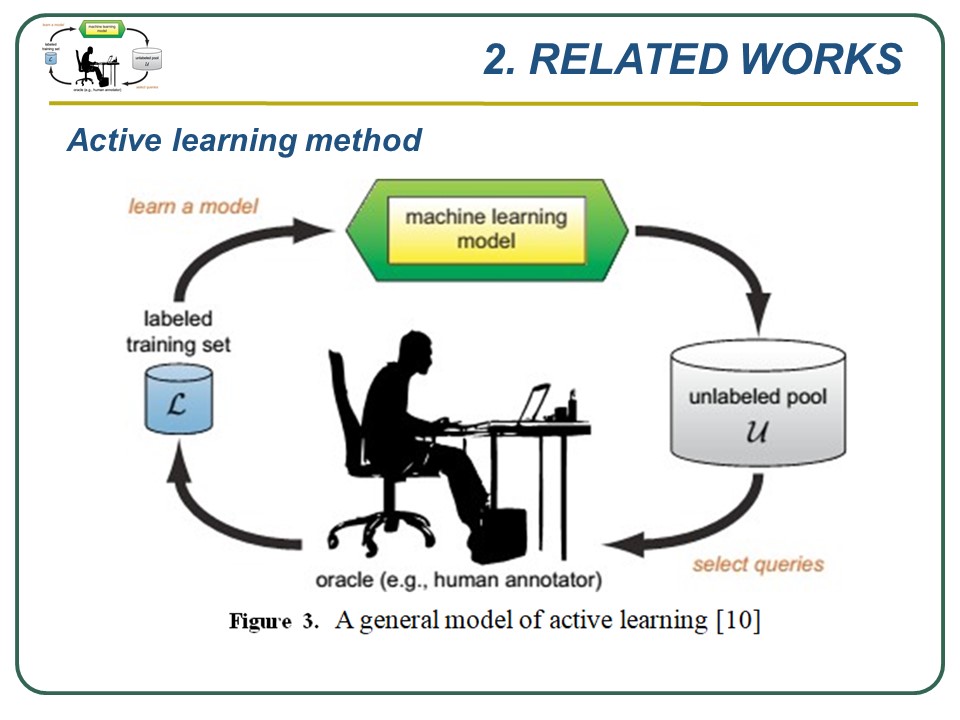 |
Next, the above figure present a general model for active learning applied for semi-supervised classification. The aims of active learning here is to build a machine learning model that can learn from unlabeled data and a small set of labeled data.
|
| ICACT20220071 Slide.09
[Big Slide]
|
Chrome Click!! |
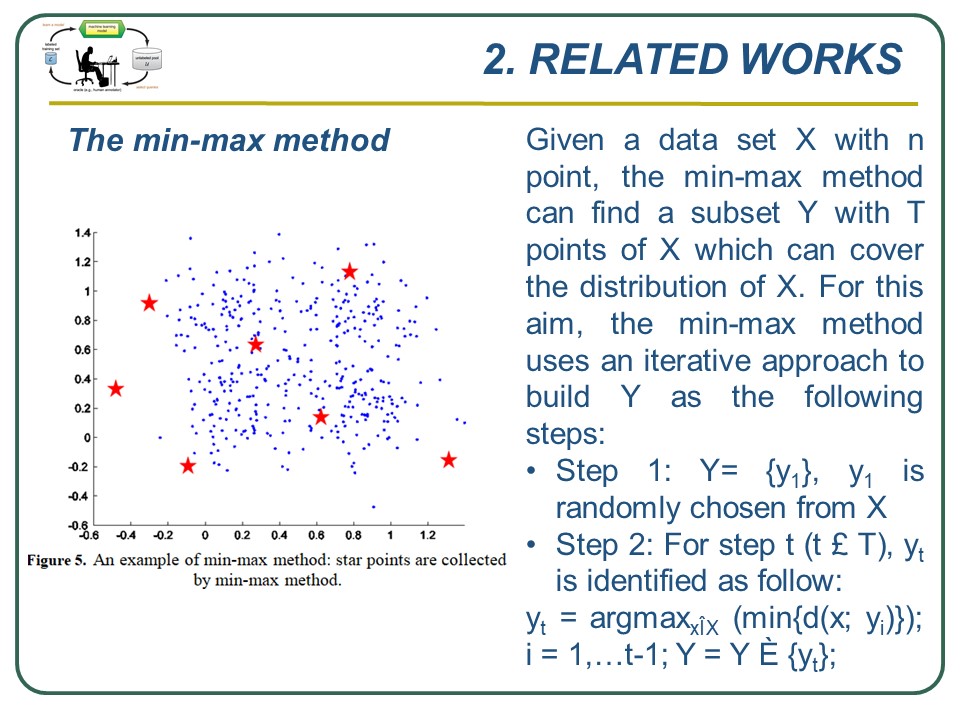 |
Another study in 2008 of Sugato Basu et al. in the paper “Active Semi-Supervision for Pairwise Constrained Clustering” showed an example of the min-max method in this case we collect 7 data point for the set Y. We can see from the figure 5, the collected set Y can cover whole data set and thus it will be helpful in the collecting points to form user questions.
|
| ICACT20220071 Slide.10
[Big Slide]
|
Chrome Click!! |
 |
This slide summarizes our proposed work.
We propose a new active learning method for collecting constraints from users/experts. These collected constraints are applied for enhancing the results of semi- supervised clustering algorithms. The main idea of our new method is based on density peak estimation and min-max strategy. The experiments conducted on some UCI data sets show the effectiveness of our method.
The detail step of our algorithm is presented in Algorithm 1.
Given a data set X with n points, the key idea of our algorithm is to apply density peaks estimation method and min-max method for building an active learning strategy. Firstly, we calculate local density and for every points of data and construct a decision graph. Secondly, we choose the peaks based on the decision graph, the set of chosen peaks are as an initial skeleton. Thirdly, we build an active learning process in which at each step, a new point is chosen following the min- max method using the skeleton and the point is used in forming user questions for getting label from users. |
| ICACT20220071 Slide.11
[Big Slide]
|
Chrome Click!! |
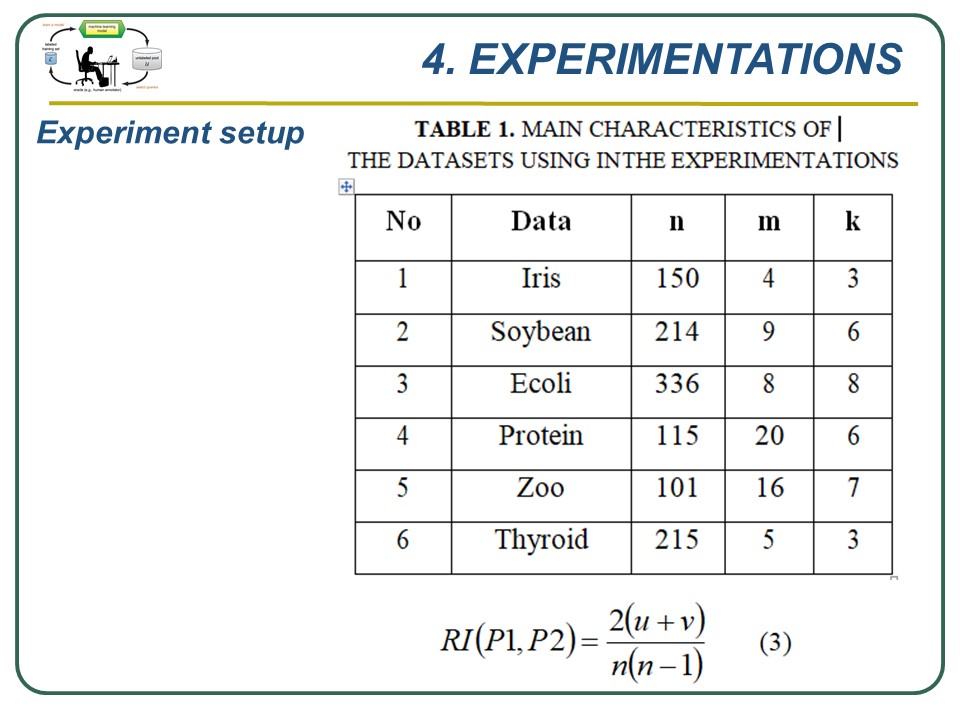 |
We conduct experiments to evaluate our new algorithm, we have used 6 data sets from UCI machine learning, at table 1 in which n is the number of data points , m is the number of attributes, and k is the number of clusters.
We use the MCSSGC, a semi-supervised graph-based clustering algorithm, to measure the effectiveness of constraints collected by our algorithm.
To estimate the clustering efficiency, we have used the Rand Index (R-I) measure (see equation 3) (The R-I calculates the agreement between the theoretical partition - P1; and the output partition - P2 of each data set by the evaluated clustering algorithm)
To compare two partitions P1 and P2, let u be the number of decisions where xi and xj are in the same cluster in both P1 and P2. Let v be the number of decisions, where the two points are put in different clusters in both P1 and P2.
The value of RI is in the interval [0…1]; R-I = 1 when the clustering result corresponds to the ground truth or user expectation. The higher the R-I, the better the result. |
| ICACT20220071 Slide.12
[Big Slide]
|
Chrome Click!! |
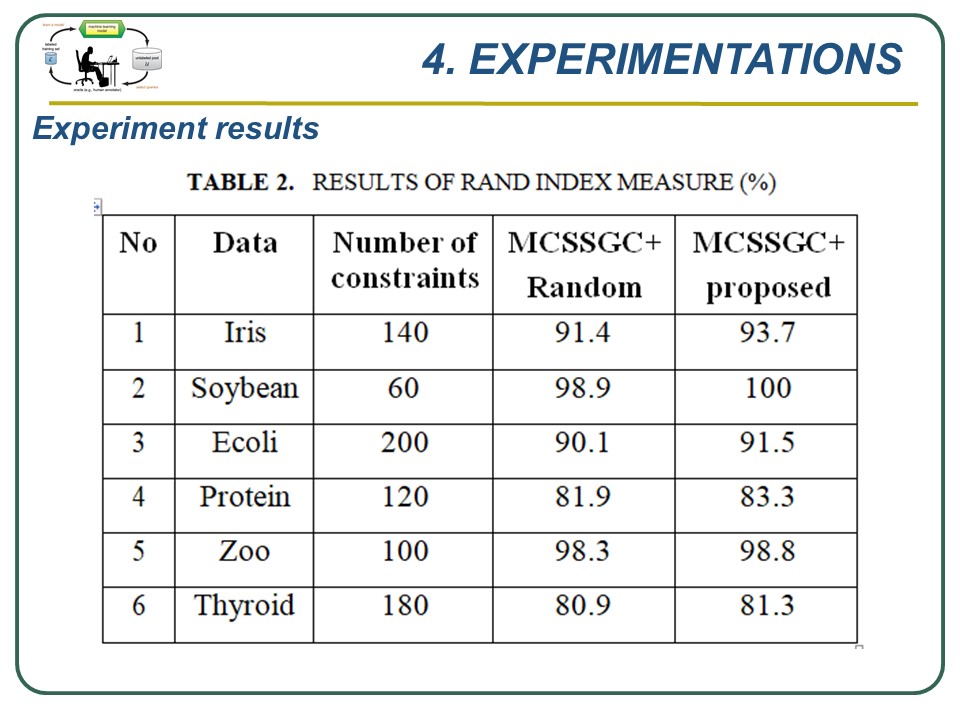 |
The following are our experimental results. Table 2 presents the Rand Index measure obtained by MCSSGC using constraints collected by our method and constraint randomly chosen and we can see that with the same constraints, the MCSSGC obtains the better results compared with using constraint collected randomly. It can be explained by the fact that our algorithm can collect constraints in the good strategy based on cluster centres and min-max method. Intuitively, our method can choose the candidates which cover the whole data set and let the clustering algorithm produces the good results. |
| ICACT20220071 Slide.13
[Big Slide]
|
Chrome Click!! |
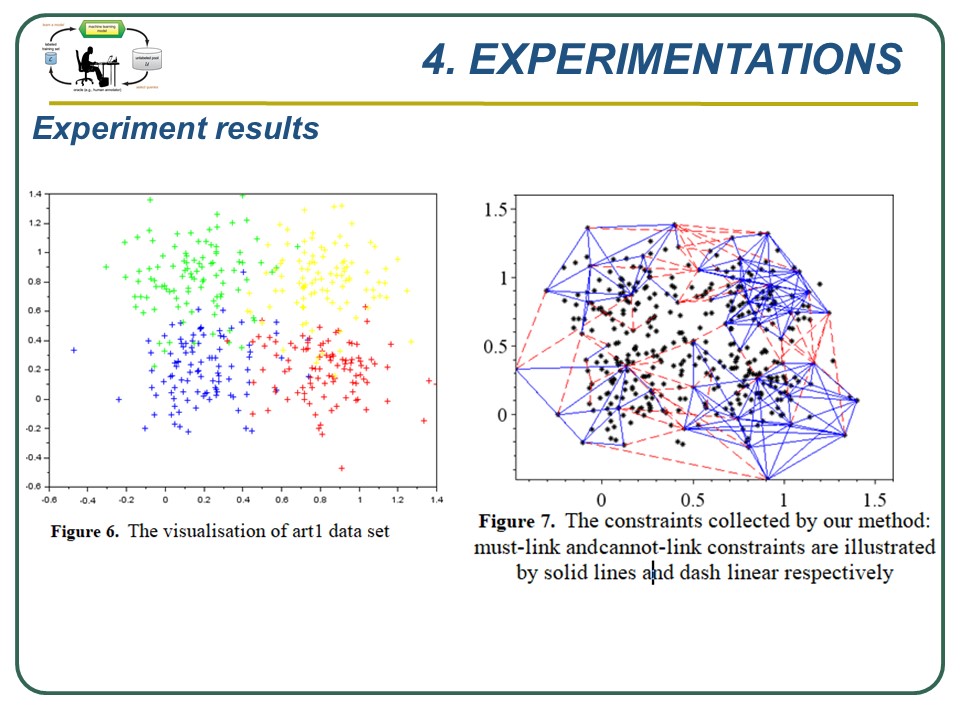 |
The above figure 6 presents an example about the constraints collected by our method for the data set Art1. The data set Art1 is a data set which has four clusters with some overlaps between clusters. As we can see in figure 7, our method can collect constraints in the border regions between clusters that are very useful for semi-supervised clustering algorithms in the clustering process, this is an evident showing the effectiveness of our method. |
| ICACT20220071 Slide.14
[Big Slide]
|
Chrome Click!! |
 |
To sum up, in this paper, we proposed an efficient active learning algorithm for collecting constraints from users/experts. Our method is based on the idea of density peaks estimation method and min-max strategy. Experiment conducted on UCI data sets show the effectiveness of our proposed method.
In the future work, we will continue to extend our method for some specific kinds of data and apply for some real KDD applications. |
| ICACT20220071 Slide.15
[Big Slide]
|
Chrome Click!! |
 |
That's all of my presentation. Thank you for listening. |








