 ICACT20220302 Slide.01
[Big Slide]
[YouTube] ICACT20220302 Slide.01
[Big Slide]
[YouTube] |
Chrome  Click!! Click!! |
 |
Hello everyone, My name is Viet-Vu Vu from Vietnam National University, Hanoi. Today, it is my pleasure to present our work in ICACT 2022. The paper’s title is: “An empirical study for density peak clustering”. |
| ICACT20220302 Slide.02
[Big Slide]
|
Chrome Click!! |
 |
Density Peak Clustering (DPC) is one of the most effective density-based clustering algorithms due to its ability to detect arbitrary clusters while being robust to noise. Since the first introduction in 2014, it has been cited a thousand times. In our paper, we present a comprehensive analysis of the DPC algorithm’s performance on some UCI and Gaussian data sets. |
| ICACT20220302 Slide.03
[Big Slide]
|
Chrome Click!! |
 |
This is the outline of our presentation. Firstly, we will talk about the density peak clustering. Secondly, we will explain the results conducted on UCI data sets and give some discussions. Finally, we conclude the talk and propose some future works.
|
| ICACT20220302 Slide.04
[Big Slide]
|
Chrome Click!! |
 |
Clustering aims to split a data set X with n elements into k clusters such that the elements in the same cluster are similar and the elements in different clusters are not. Although this is a classical problem of machine learning and has been studied since the 50s of the 20th centuries, it still attracts many researchers these days. The essence of the clustering is to discover hidden structures behind the data, detect the relationships between elements, and anomalies in the data.
Different clustering strategies have been reported over the years and can be categorized as Centroid-based (such as K-means, CLARA, Fuzzy C-Means), Graph-based (such as SNN, CHAMELEON), and Density-based (such as DBSCAN, OPTICS). However, most of these algorithms suffer from choosing their appropriate parameters for different datasets, for example the density threshold.
In 2014, Rodriguez and Laio proposed a novel density-based clustering algorithm through fast search and density peaking (named as DPC). The algorithm attracts many researchers' attention and has a thousand citations till now.
|
| ICACT20220302 Slide.05
[Big Slide]
|
Chrome Click!! |
 |
The density peak clustering is proposed in 2014 which is based on two intuitive assumptions: (1) Cluster centers have higher densities than the surrounding regions; (2) Distances among cluster centers are relatively large. To utilize the assumptions, two important factors are computed for each data point 𝑥_𝑖, namely the local density 𝜌_𝑖 and its relative distance 𝛿_𝑖. This calculation depends on the value 𝑑_𝑖𝑗 which represents the distance between the point 𝑥_𝑖 and 𝑥_𝑗 (here, it is the Euclidean distance); and the cut-off distance 𝑑_𝑐 which represents the neighborhood radius of the data point. |
| ICACT20220302 Slide.06
[Big Slide]
|
Chrome Click!! |
 |
Here, on the other hand, the relative distance 𝛿_𝑖 of the data point 𝑥_𝑖 to their nearest point 𝑥_𝑗 with higher density 𝜌_𝑗 is defined as the equation (2). The idea of DPC is based on the concept of BLOB detection in which the boundaries where the water from two markers meets each other indicates where the BLOBs should be split as shown in the figure on the slide.
|
| ICACT20220302 Slide.07
[Big Slide]
|
Chrome Click!! |
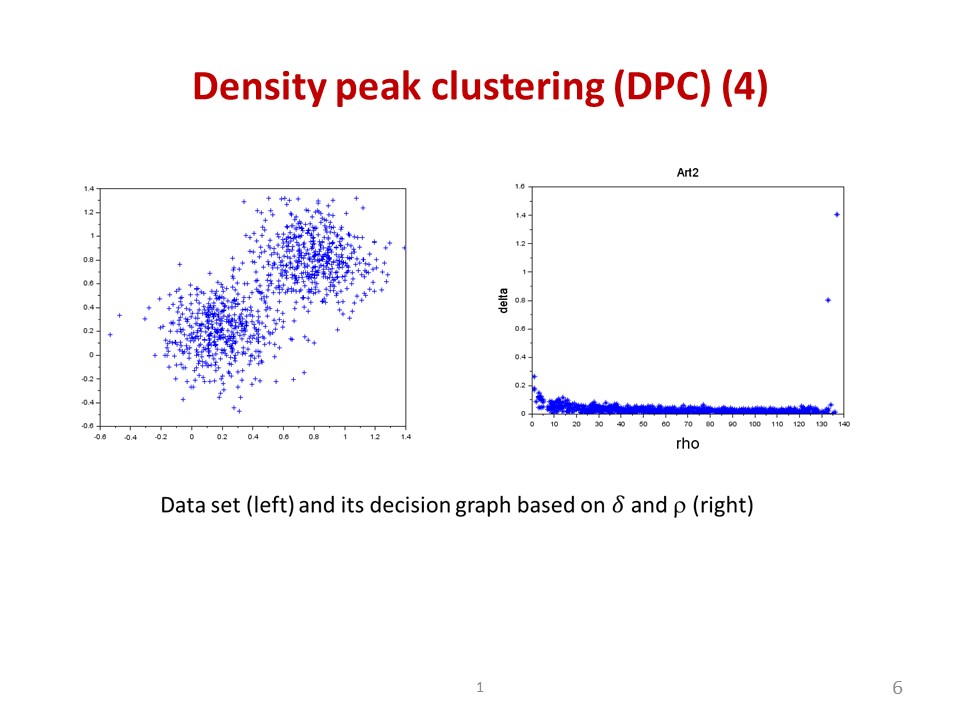 |
From delta and rho mentioned above, the DPC algorithm constructs a decision graph in which we can easily identify the number of clustering for data sets. In the slide shown an example for a data set and its decision graph with 2 cluster centers identified. |
| ICACT20220302 Slide.08
[Big Slide]
|
Chrome Click!! |
 |
The steps in DPC algorithm are summarized in Algorithm 1. After calculating the local density and the relative distance of all data points (steps 1 and 2), the DPC algorithm establishes a decision graph (step 3). From the decision graph, it has been shown that the point with high values of both 𝜌_𝑖 and 𝛿_𝑖 is called a peak, then the cluster center can be selected from those peaks (steps 3 and 4). In the final step, the non-center points are assigned to the same cluster as their nearest neighbor peak (step 5). Suppose that there are n points in the dataset. The time complexity of DPC depends on the following parts: (1) calculating the Euclidean distance between points takes 𝑂(𝑛^2); (2) computing the local density and relative distance for all points takes (3) the assignment of non-center points to the clusters takes 𝑂(𝑛). Therefore, the total approximate time complexity of DPC is 𝑂(𝑛^2). |
| ICACT20220302 Slide.09
[Big Slide]
|
Chrome Click!! |
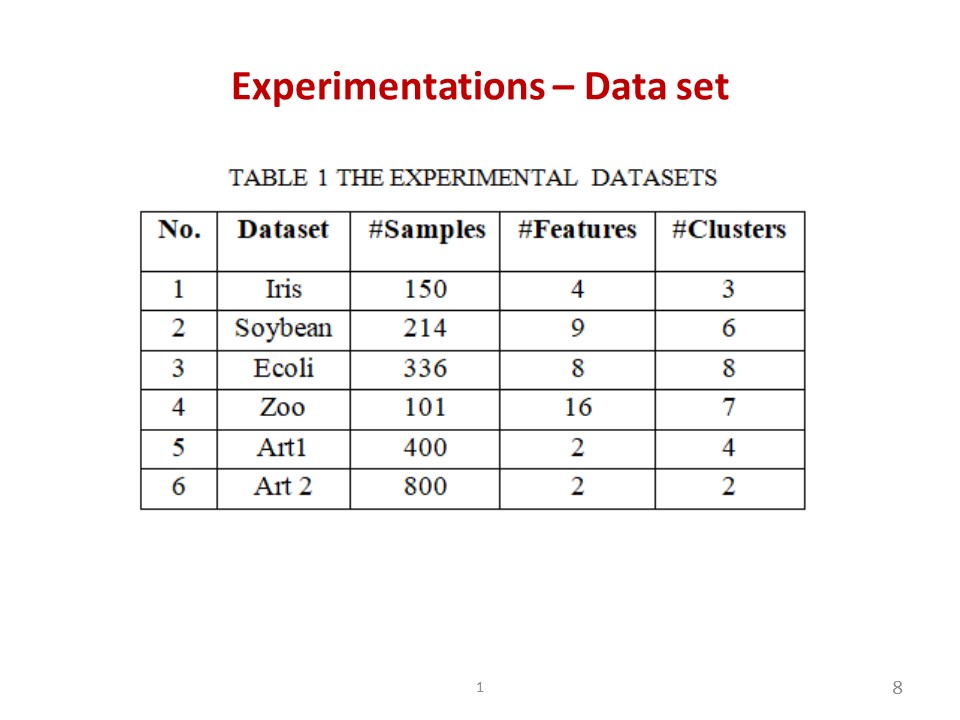 |
To evaluate the efficiency of DPC algorithm, we use real-world datasets from UCI and synthetic datasets Art1 and Art2 – both are with Gaussian distribution. These UCI datasets are widely used in the research community to compare and evaluate the clustering quality. Details of the datasets are given in Table 1. |
| ICACT20220302 Slide.10
[Big Slide]
|
Chrome Click!! |
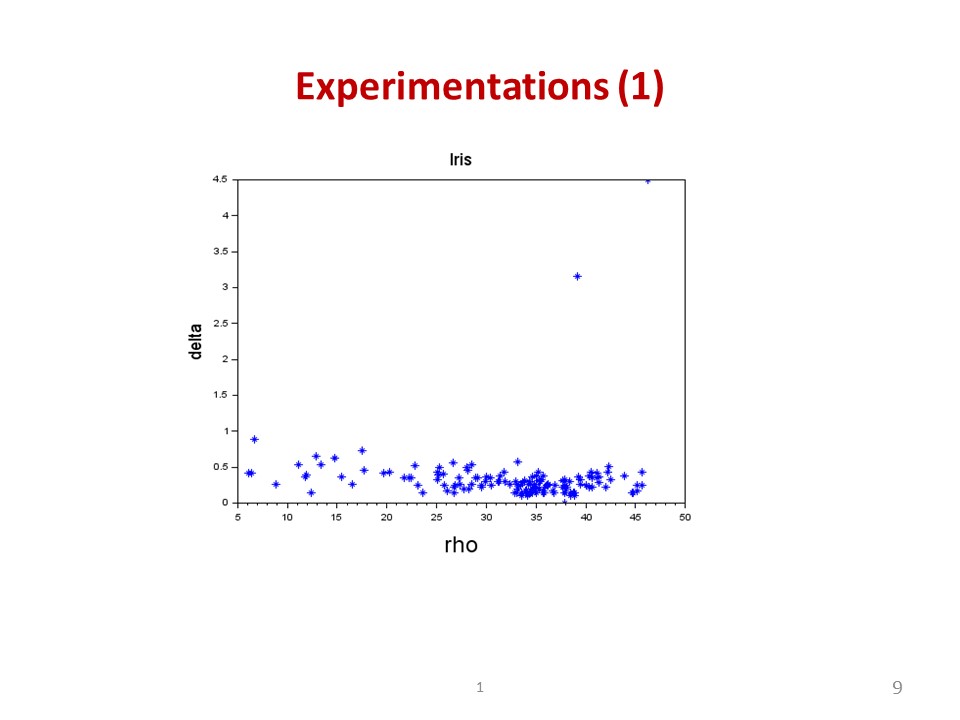 |
We first look at the Iris dataset in this slide, which is a 150-sample dataset. Two among three clusters of the dataset are very close to each other. In this case, only 2 peaks can be identified conveniently from the decision graph of Iris. Obviously, when clusters overlap, DPC algorithm finds it difficulty in determining the cluster centers. |
| ICACT20220302 Slide.11
[Big Slide]
|
Chrome Click!! |
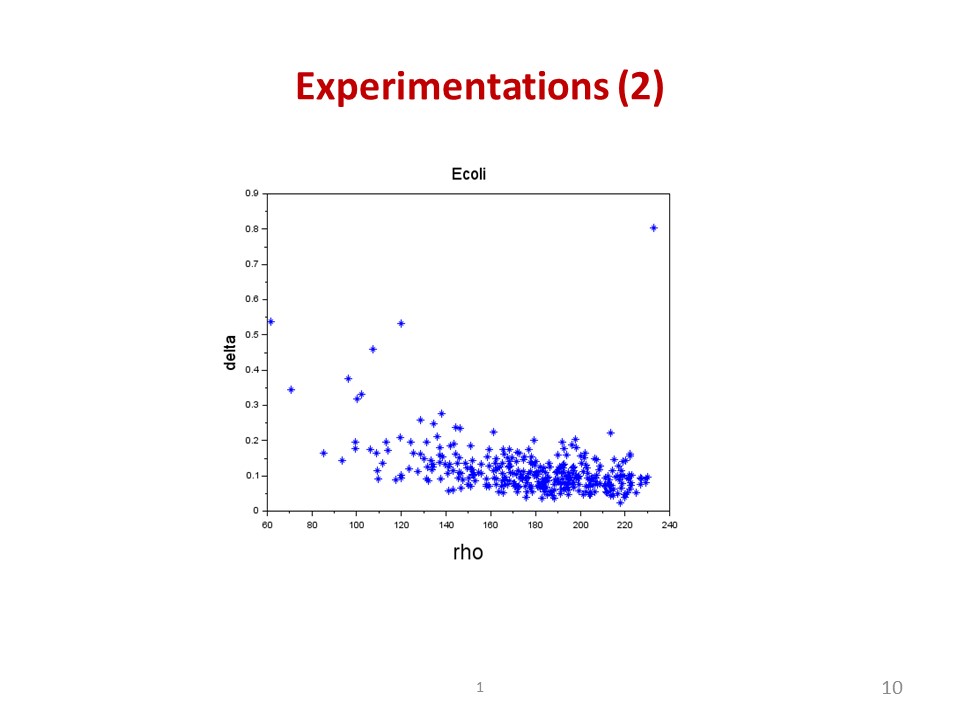 |
Here, the result for Ecoli dataset is shown in the slide. The dataset involves 8 clusters of hugely different sizes. One cluster can have a few points while another contains hundreds of points. Again, for those with hugely different in sizes, DPC has not proven its ability to determine peaks reasonably. |
| ICACT20220302 Slide.12
[Big Slide]
|
Chrome Click!! |
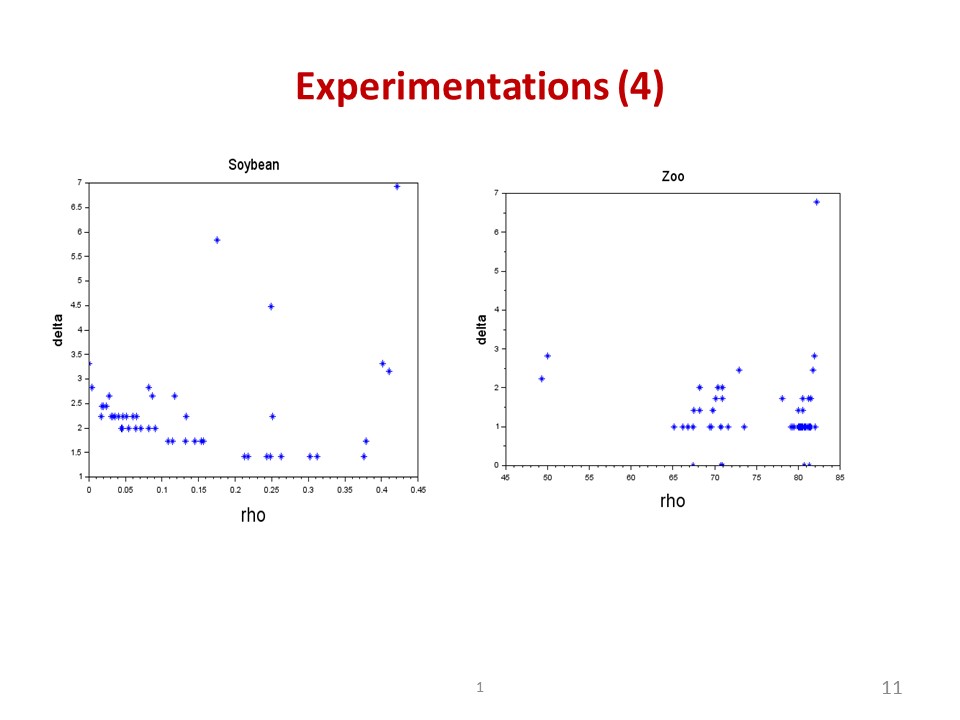 |
The Soybean dataset consists of 4 clusters. From its decision graph as shown in the left slide, it can be seen that if we determine 4 peaks at the top right position, there will be two points falling into the same cluster. Similar to Soybean, it is not easy to determine all 7 cluster centers in the Zoo dataset as illustrated in right of slide. |
| ICACT20220302 Slide.13
[Big Slide]
|
Chrome Click!! |
 |
From the analysis mentioned above, we can deeply understand the efficiency of DPC and also point out some comments as follows. First, it is difficult for DPC in determining the cluster centers where the dataset is unbalanced overlapped or the data has clusters in which there are local minima. Second, a combination with other algorithms to speed up the DPC algorithm can be considered, for example to reduce the time complexity of calculating the distance between points. The study to apply different types of distances for each dataset can also be further considered. Finally, the research and development of semi-supervised clustering algorithms based on DPC is also a promising research direction. |
| ICACT20220302 Slide.14
[Big Slide]
|
Chrome Click!! |
 |
In this paper, we have studied and evaluated the DPC algorithm. A range of experiments were conducted not only on read datasets but also on synthetic data in order to verify its performance. The obtained results show that DPC outperform K-means in terms of the Rand index, however, its advantages and disadvantages have also been depicted. To sum up, we highlight several issues that are limiting its practical application and propose some directions of further development of DPC as follows:
First, it is difficult for DPC in determining the cluster centers where the dataset is unbalanced overlapped or the data has clusters in which there are local minima.
Second, a combination with other algorithms to speed up the DPC algorithm can be considered, for example to reduce the time complexity of calculating the distance between points. The study to apply different types of distances for each dataset can also be further considered.
Finally, the research and development of semi-supervised clustering algorithms based on DPC is also a promising research direction. |
| ICACT20220302 Slide.15
[Big Slide]
|
Chrome Click!! |
 |
That's all of my presentation. Thank you very much for your attention. |








